GARCH-based Asymmetric Least Squares Risk Measures
Distribution of risk measures
We calculate the quantiles, expectiles and extremiles from the standard residuals:
First, we compute the risk measures via QMLE at \(\tau =\{1\%,5\%,10\%\}\).
Second, we compute the risk measures via (QMLE) bootstrap at \(\tau =\{1\%,5\%,10\%\}\).
Empirical Data
We collect the daily price data of S\&P 500, EUR/USD, BTC/USD, ETH-USD, BNB-USD, DOGE-USD and ADA-USD
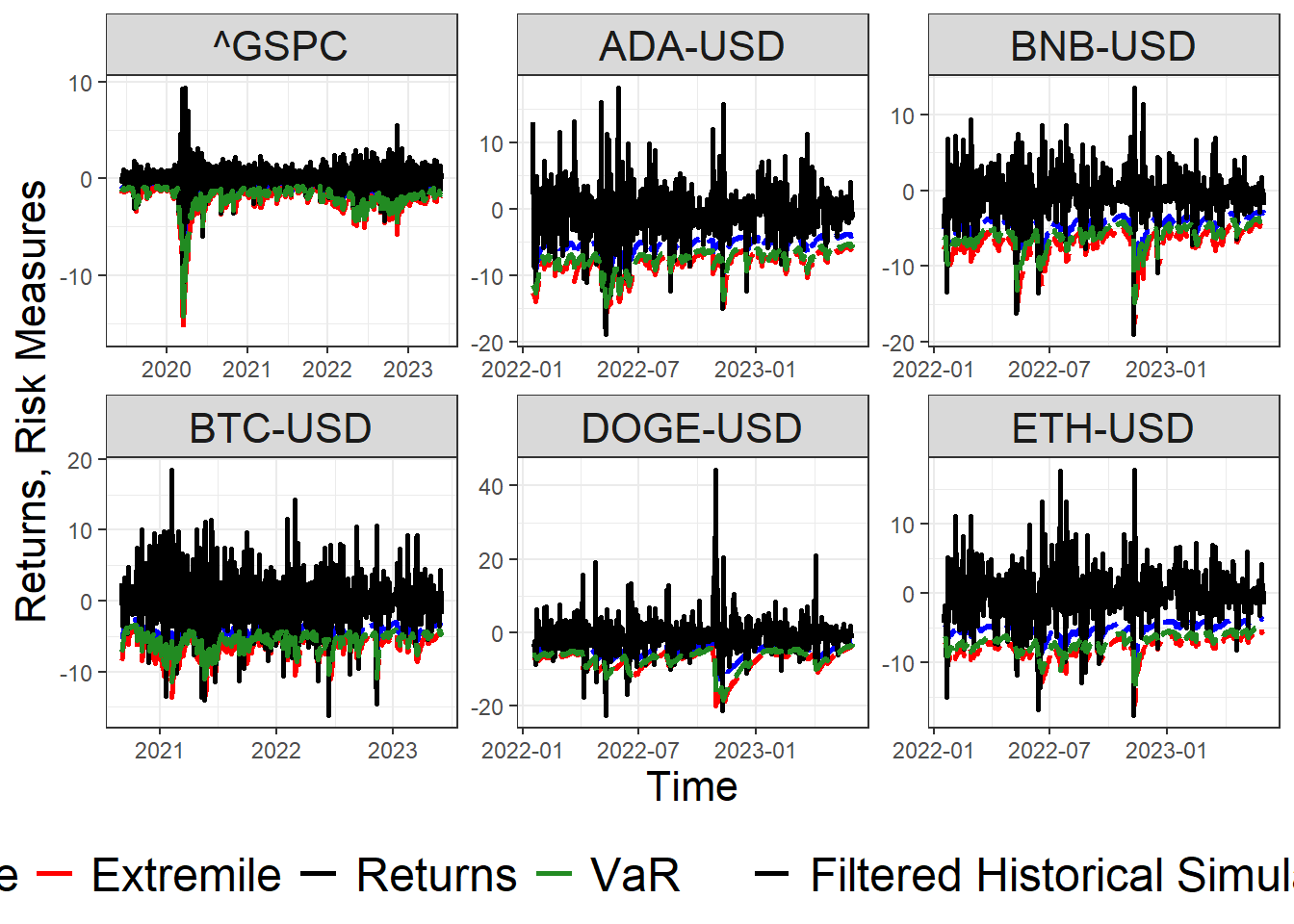
The following dashboard summarizes all risk measures considering Historical, Parametric and Filtered Historical Simulation.
Figure below show the Filtered Historical Simulation risk measures for several assets for \(\tau = 0.05\).
risk.data =readRDS('C:/Users/Olive/Documents/Github/Thesis/GARCH-Based Asymetric Least Squares for Financial Time Series/Dashboards/GARCH-Based ALS Empirical Analysis/empirical/risk.data.RDS')risk.data %>%filter(window %in%c('expanding')) %>%filter(type %in%c('Filtered Historical Simulation','Returns')) %>%filter(measure %in%c('VaR','Returns','Expectile','Extremile')) %>%filter(level %in%0.05) %>%filter(!(ticker %in%c('EURUSD=X'))) %>%ggplot() +geom_line(aes(x = date, y = estimate, color = measure, linetype = type), linewidth =1) +scale_color_manual(values =c('Returns'='black' ,'Extremile'='red','Expectile'='blue','VaR'='forestgreen','Expected Shortfall'='purple')) +scale_linetype_manual(values =c('Returns'='solid','Filtered Historical Simulation'='longdash')) +theme_bw() +labs(x ='Time', y ='Returns, Risk Measures') +facet_wrap(~ticker, scales ='free') +theme(legend.title =element_blank(),legend.position ='bottom',legend.text =element_text(size =18),axis.title =element_text(size =16),strip.text =element_text(size =16))
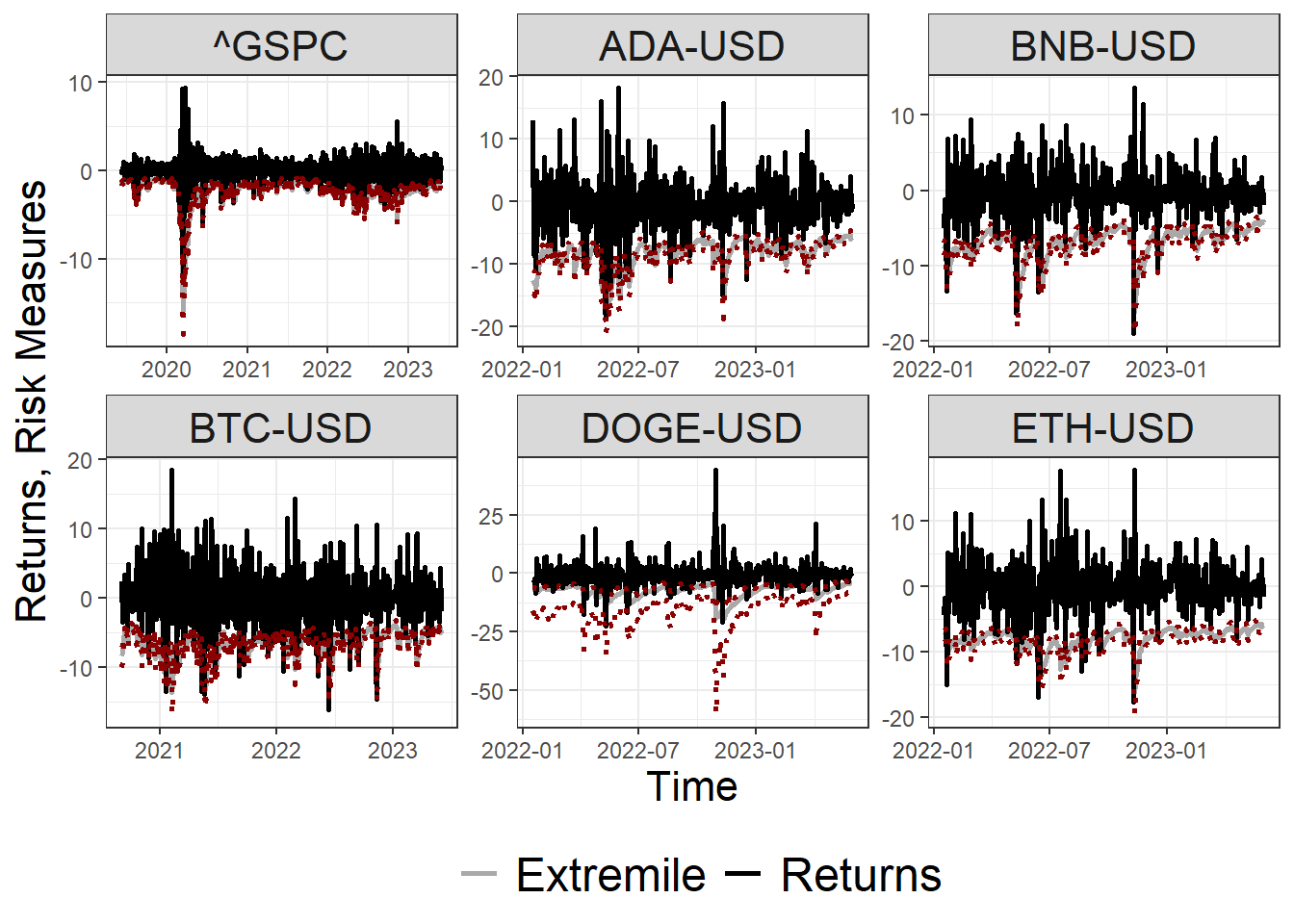
Bootstrap Confidence Interval
The following dashboard reports the bootstrap confidence interval of all Filtered Historical Simulation risk measures.
Figure below shows the bootstrap confidence interval of the \(\tau\)-th Extremile (\(\tau =0.05\)) risk measure considering a bootstrap confidence level of \(\alpha = 0.05\).
ci.data =readRDS('C:/Users/Olive/Documents/Github/Thesis/GARCH-Based Asymetric Least Squares for Financial Time Series/Dashboards/GARCH-Based ALS Empirical Analysis/empirical_ci/ci.data.RDS')ci.data %>%filter(window %in%c('expand')) %>%filter(measure %in%c('Returns','Extremile')) %>%filter(level %in%0.05) %>%filter(!(ticker %in%c('EURUSD=X'))) %>%fill(c(lower_bound,upper_bound)) %>%ggplot() +geom_line(aes(x = date, y = estimate, color = measure), linetype ='solid', linewidth =1) +geom_line(aes(x = date, y = upper_bound), linetype ='dotted', color ='darkred',linewidth =1) +geom_line(aes(x = date, y = lower_bound), linetype ='dotted', color ='darkred', linewidth =1) +scale_color_manual(values =c('Returns'='black' ,'Extremile'='darkgrey','Expectile'='blue','VaR'='forestgreen')) +labs(x ='Time', y ='Returns, Risk Measures') +theme_bw() +facet_wrap(~ticker, scales ='free') +theme(legend.title =element_blank(),legend.position ='bottom',legend.text =element_text(size =18),axis.title =element_text(size =16),strip.text =element_text(size =16))
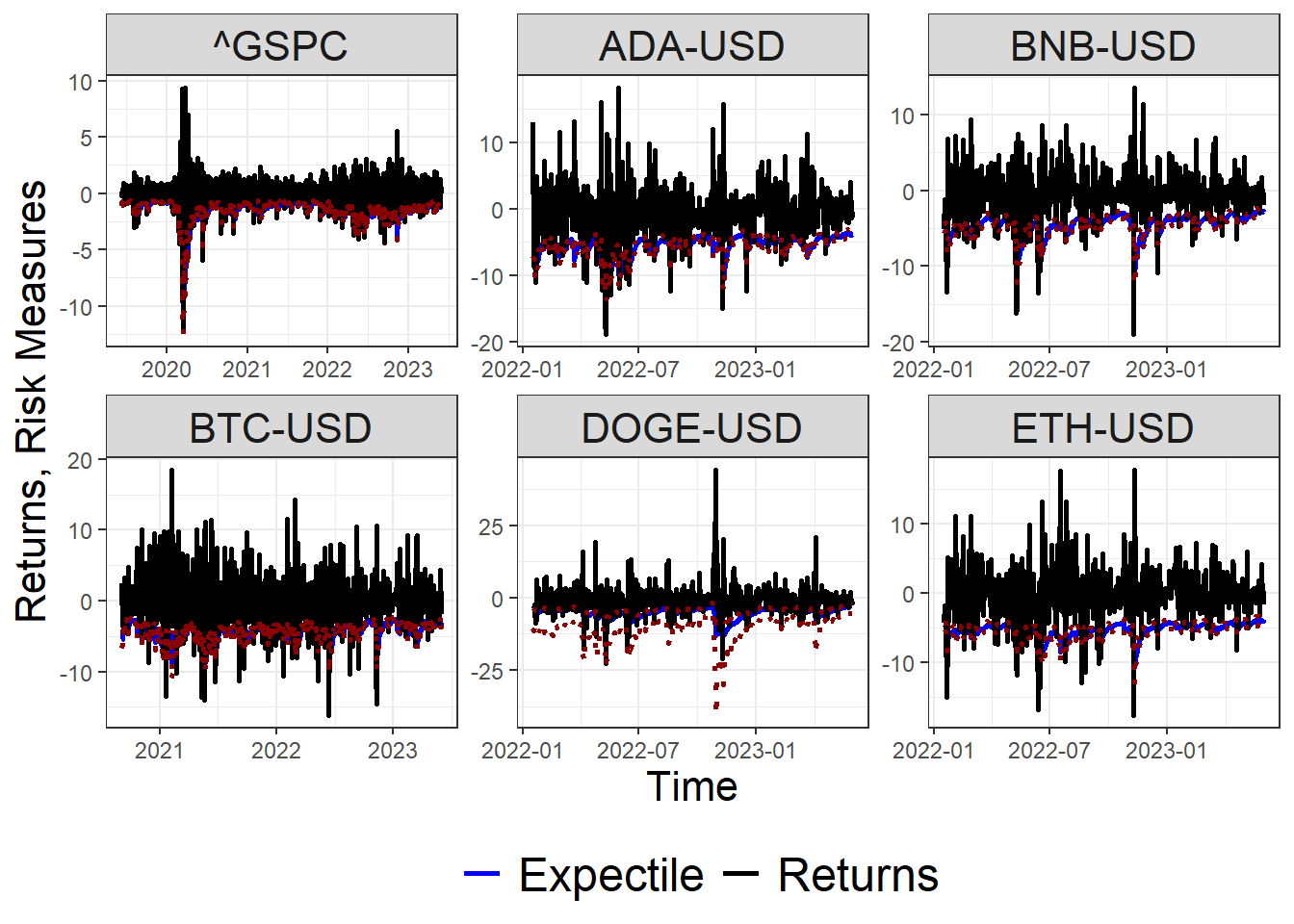
Likewise, Figure below shows the bootstrap confidence interval of the \(\tau\)-th Expectile (\(\tau =0.05\)) risk measure considering a bootstrap confidence level of \(\alpha = 0.05\).
ci.data %>%filter(window %in%c('expand')) %>%filter(measure %in%c('Returns','Expectile')) %>%filter(level %in%0.05) %>%filter(!(ticker %in%c('EURUSD=X'))) %>%fill(c(lower_bound,upper_bound)) %>%ggplot() +geom_line(aes(x = date, y = estimate, color = measure), linetype ='solid', linewidth =1) +geom_line(aes(x = date, y = upper_bound), linetype ='dotted', color ='darkred',linewidth =1) +geom_line(aes(x = date, y = lower_bound), linetype ='dotted', color ='darkred', linewidth =1) +scale_color_manual(values =c('Returns'='black' ,'Extremile'='darkgrey','Expectile'='blue','VaR'='forestgreen')) +labs(x ='Time', y ='Returns, Risk Measures') +theme_bw() +facet_wrap(~ticker, scales ='free') +theme(legend.title =element_blank(),legend.position ='bottom',legend.text =element_text(size =18),axis.title =element_text(size =16),strip.text =element_text(size =16))
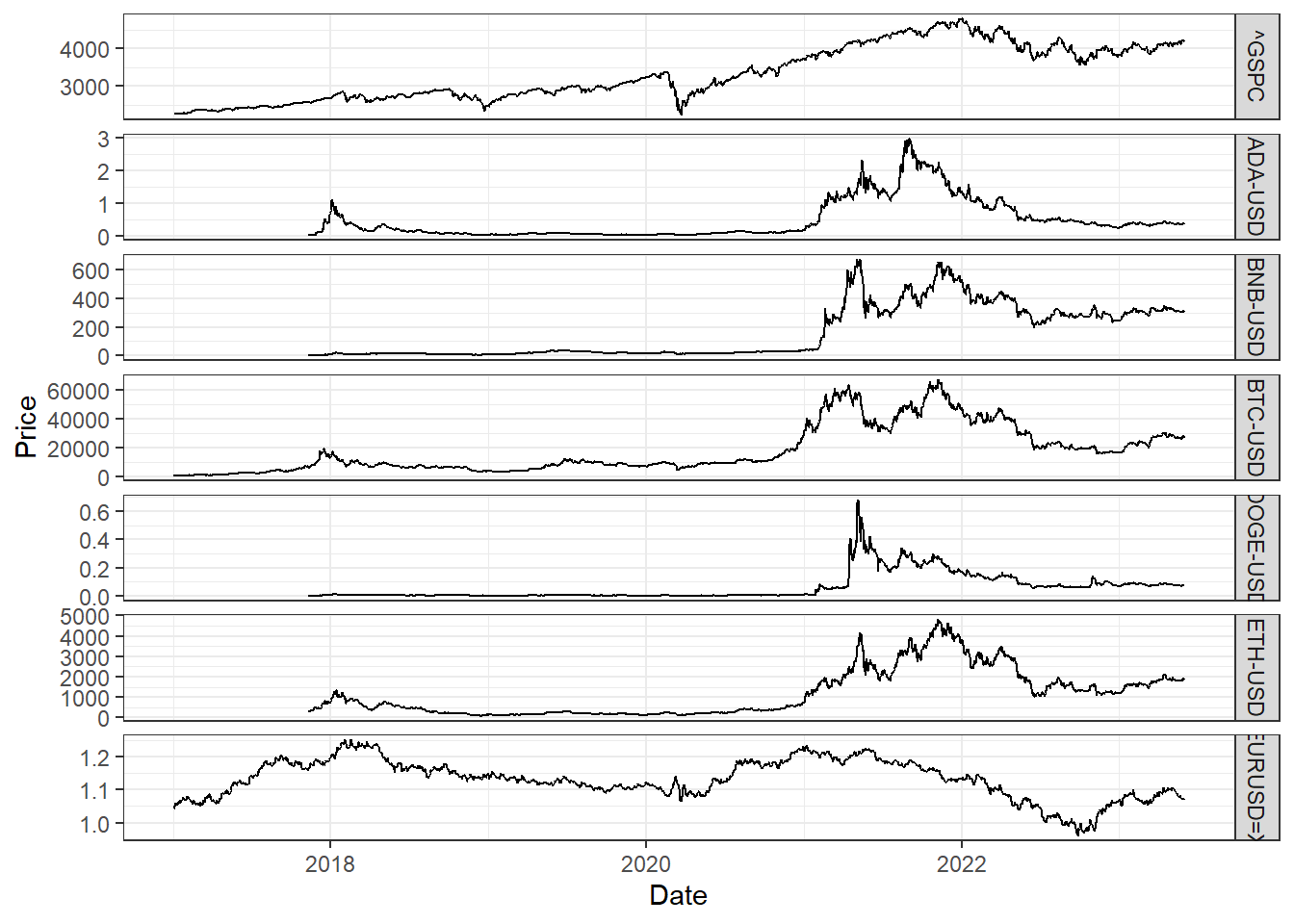
Cryptocurrencies reached their peak values during the market’s surge in late 2021. However, many digital assets experienced significant price corrections in the following year. In particular, Bitcoin reached its record-breaking all-time high of \(\$67,566.83\) on November 8, 2021, although experienced a substantial decline in value, trading at \(\$15,787.28\) on November 21, 2022.
data %>%ggplot() +geom_line(aes(x = date, y = price)) +labs(x ='Date', y ='Price') +facet_grid(ticker ~ ., scales ='free') +theme_bw()
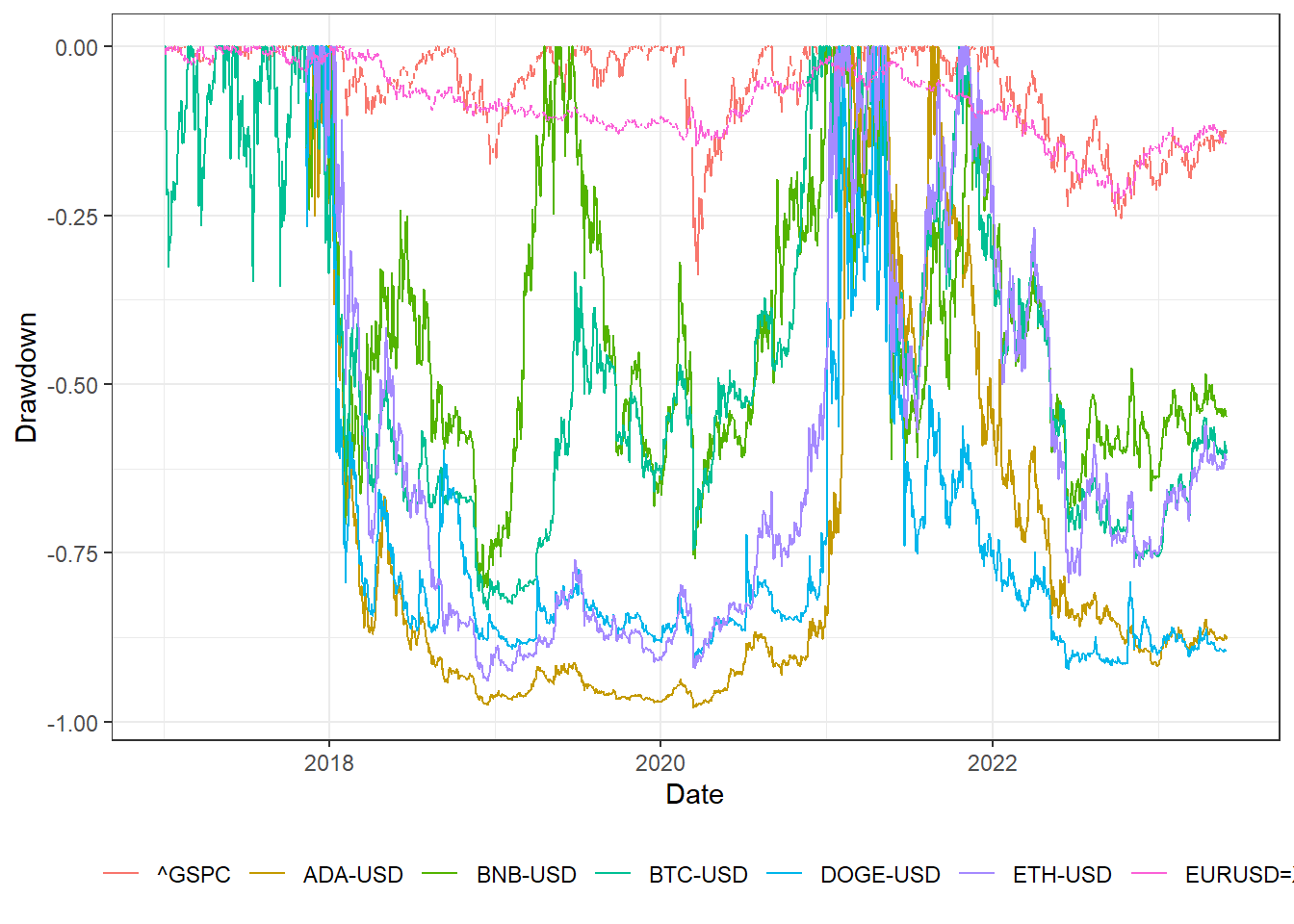
The figure below presents a comparative analysis of historical drawdowns among various cryptocurrencies, namely Bitcoin (BTC-USD), Bitcoin Cash (BTC/USD), Ethereum (ETH-USD), Binance Coin (BNB-USD), Dogecoin (DOGE-USD), and Cardano (ADA-USD), with respect to the S&P 500 and EUR/USD. It is evident that Cardano, Ethereum, Dogecoin, Bitcoin, and Binance Coin have experienced significant declines, surpassing 80% since reaching their respective peak values. In contrast, the drawdowns observed in the S&P 500 and EUR/USD have been relatively milder, hovering around 30%. These results show the substantial price fluctuations and volatility observed within the cryptocurrency market while highlighting the comparatively more stable performance of traditional financial benchmarks like the S&P 500 and EUR/USD.